Aprimorando o uso de
Algoritmos Genéticos na geração de Regras de Associação
emmanuel@ele.puc-rio.com.br
hquintel@unisys.com.br
savio.augusto@rj.previdenciasocial.gov.br
Abstract. Este artigo descreve os resultados da investigação sobre a associação
entre funções de avaliação utilizadas em Algoritmos Genéticos por evolução de
regras de associação no processo de descoberta de conhecimento implícito em
Banco de Dados (KDD – Knowledge Discovery Database) e características do banco
de dados obtidas nos conjuntos de dados já estudados para o problema de
classificação. O problema de classificação
aqui tratado se refere ao processo de evolução de regras que melhor definem a
diferença entre os grupos estudados.
Como resultado são apresentados conjuntos de regras descrevendo o perfil
de cada uma das dez funções de avaliação estudadas na ferramenta Rule-Evolver
com base em características do banco de dados como a quantidade de registros,
quantidade de variáveis categóricas, quantidade de variáveis contínuas, grau de
interseção entre os grupos e o tamanho do espaço de busca. Algumas hipóteses levantadas como o
relacionamento entre as características dos bancos de dados e a indicação do
uso das funções de avaliação são aqui avaliadas. As outras hipóteses se referem a verificação da importância das
funções de avaliação no problema e da sua aplicabilidade a grandes bases de
dados. O estudo das funções de
avaliação foi realizado com a utilização da ferramenta Rule-Evolver para a
elaboração de uma base de dados com o resultado de experimentos realizados com
trinta e dois bancos de dados. A
prospecção de conhecimento é feita com a aplicação do processo de Descoberta de
Conhecimento (KDD) com a utilização da ferramenta Rule-Evolver e da Análise de
Correspondência Múltipla.
1. Introdução
Atualmente empresas
que possuem grandes bases de dados estão construindo seus sistemas de apoio à
decisão e, para isto, necessitam de um ambiente, de preferência externo ao
operacional, onde possam efetuar consultas e estudos e desta forma extrair
algum conhecimento que contribua para melhorar a sua performance de vendas ou
aumentar o conhecimento a respeito do comportamento de seus clientes, por
exemplo. A informação incorpora-se hoje como um fator de produção.
A este ambiente chamamos de Data Warehouse cujo objetivo é o de
organizar, gerenciar e integrar os diversos conjuntos de dados da empresa num
único local para que com as ferramentas de exploração ofereça infra-estrutura
suficiente no Processo de Descoberta de Conhecimento conhecido como KDD
(Knowledge Discovery in Database).
O Processo de
Descoberta de Conhecimento é a “extração não trivial de informação implícita,
potencialmente útil e anteriormente desconhecida do banco de dados” [FRAW91] e também é um campo
multidisciplinar envolvendo as áreas de Estatística, Banco de Dados e
Inteligência Computacional [PASS00].
A etapa principal deste processo é a
Mineração de Dados, que pode ser definido como “a procura de informação valiosa
em grandes volumes de dados” e, atualmente, para a Mineração de Dados
Preditiva, “a procura de padrões marcantes em grandes volumes de dados que
podem ser generalizados para futuras decisões”
[WEIS98]. A Mineração de Dados Preditiva é um conceito
que está evoluindo do suporte à decisão para a tomada de decisão.
Segundo a empresa
Forrester Reasearch, a capacidade de extrair informações valiosas do próprio
banco de dados é uma das poucas áreas do negócio em que se conseguem vantagens
competitivas tangíveis. Um exemplo é a
seguradora Farmers Group que cobrava mais pelos seguros de modelos esportivos
de carros. Uma análise mais apurada
descobriu que se a casa tivesse um outro carro além do esportivo, os índices de
colisões dos carrões não eram muito diferentes do que os de um modelo
comum. Com esta informação o
faturamento cresceu 4,5 milhões de dólares em dois anos e a sua participação nesse
segmento de mercado dobrou. PASSOS [PASS00]
exemplifica, num estudo de caso, esta busca de conhecimento aplicando
técnicas de Inteligência Computacional.
A área de Mineração de Dados nasceu
dentro do campo da estatística com a utilização de técnicas clássicas como a
regressão, análise estatística e uso do
Qui-quadrado em tabulações de dados com o objetivo de explorar o conhecimento
em bases de dados. A forma com que o
conhecimento obtido é expresso também se mostra diferente. Se por um lado no campo da estatística o
conhecimento é expresso por meio de modelos, medidas, gráficos, necessitando de
uma interpretação nem sempre trivial, por outro este conhecimento pode ser
expresso por meio de regras que, por exemplo, podem descrever o conjunto de
dados. Existem diferentes formas de
conhecimento que podem ser extraídas dos dados [ADRI96]: Conhecimento superficial, Conhecimento Multi-dimensional,
Conhecimento escondido e, Conhecimento
profundo.
Enquanto que as
ferramentas OLAP e o SQL são voltadas principalmente para o conhecimento
superficial, Data Mining aborda básicamente dois tipos de problemas: Descoberta
de conhecimento e Predição, na busca de conhecimento escondido [WEIS98].
Este trabalho visa
promover avanços práticos para aplicações comerciais como, por exemplo, a construção
de perfis de consumidores, empresas, concorrentes, etc. Esse esforço é um dos
usos competitivos de Tecnologia da Informação pesquisado por QUINTELLA [QUIN97].
2 Metodologia
A elaboração da base de dados de
análise contou com um total de 320 experimentos correspondendo a execução do
algoritmo para cada um dos 32 bancos de dados e para cada uma das dez funções
de avaliação da ferramenta Rule-Evolver.
Uma descrição resumida das bases de dados, encontram-se nos Quadros 1 e
2. A definição dos experimentos para a
geração da base de dados encontra-se especificada nos Quadros 3 e 4. As etapas do Processo de Descoberta de
Conhecimento (KDD) aplicada nesta base de dados são descritas nos tópicos
seguintes. Este processo consiste, a
princípio, em seis estágios: Seleção de Dados, Limpeza, Enriquecimento,
Transformação, Mineração e
Avaliação/Verificação.
2.1 Seleção de dados
As bases de dados utilizadas
encontram-se relacionadas abaixo de forma resumida. Encontram-se descritos o conteúdo e o problema estudado [SHIH99].
|
Sigla |
Nome
do Banco |
Sigla |
Nome
do Banco |
|
BCW |
WISCONSIN BREAST CANCER |
SAT |
STATLOG SATELLITE IMAGE |
|
BLD |
BUPA LIVER DISORDERS |
SEG |
IMAGE SEGMENTATION |
|
BOS |
BOSTON HOUSING |
SMO |
ATTITUDE TOWARDS SMOKING
RESTRICTIONS |
|
CMC |
CONTRACEPTIVE METHOD CHOICE |
TAE |
TA EVALUATION |
|
DNA |
STATLOG DNA |
THY |
THYROID DISEASE |
|
HEA |
STATLOG HEART DISEASE |
VEH |
STATLOG VEHICLE SILHOUETTE |
|
LED |
LED DISPLAY |
VOT |
CONGRESSIONAL VOTING
RECORDS |
|
PID |
PIMA INDIAN DIABETES |
WAV |
WAVEFORM |
Fonte: Lim &Loh &Shih, A comparison of prediction accuracy,
complexity, and training time of thirty-three old and new classification
Algorithms - 1999
Quadro 1. – Identificação das bases
de dados utilizadas
Para cada um dos bancos de dados acima foi
gerado, segundo [SHIH99], um novo
conjunto com perturbações aleatórias que se encontram definidos no Quadro 2.
|
|
|
|
Quantidade de atributos originais |
Atributos aleatórios |
||||||||
|
Nome |
Tamanho |
# classes |
Numérico |
Categorias |
Total |
Numérico |
Categórico |
|||||
|
|
|
|
|
2 |
3 |
4 |
5 |
25 |
26 |
|
|
|
|
bcw |
683 |
2 |
9 |
|
|
|
|
|
|
9 |
9
UI(1,10) |
|
|
Cmc |
1473 |
3 |
2 |
3 |
|
4 |
|
|
|
9 |
6
N(0,1) |
|
|
Dna |
2000 |
3 |
|
|
|
60 |
|
|
|
60 |
|
20
UI(1,4) |
|
Hea |
270 |
2 |
7 |
3 |
2 |
1 |
|
|
|
13 |
7
N(0,1) |
|
|
Bos |
506 |
3 |
12 |
1 |
|
|
|
|
|
13 |
12
N(0,1) |
|
|
Led |
2000 |
10 |
|
7 |
|
|
|
|
|
7 |
|
17
UI(1,2) |
|
Bld |
345 |
2 |
6 |
|
|
|
|
|
|
6 |
9
N(0,1) |
|
|
Pid |
532 |
2 |
7 |
|
|
|
|
|
|
7 |
8
N(0,1) |
|
|
Sat |
4435 |
6 |
36 |
|
|
|
|
|
|
36 |
24
UI(20,160) |
|
|
Seg |
2310 |
7 |
19 |
|
|
|
|
|
|
19 |
9
N(0,1) |
|
|
Smo |
1855 |
3 |
3 |
3 |
1 |
|
1 |
|
|
8 |
7
N(0,1) |
|
|
Thy |
3772 |
3 |
6 |
15 |
|
|
|
|
|
21 |
4
U(0,1) |
10
UI(1,2) |
|
Veh |
846 |
4 |
18 |
|
|
|
|
|
|
18 |
12
N(0,1) |
|
|
Vot |
435 |
2 |
|
|
16 |
|
|
|
|
16 |
|
14
UI(1,3) |
|
Wav |
600 |
3 |
21 |
|
|
|
|
|
|
21 |
19
N(0,1) |
|
|
Tae |
151 |
3 |
1 |
2 |
|
|
|
1 |
1 |
5 |
5 N(0,1) |
|
Fonte: Lim, Loh e Shih, A comparison
of prediction accuracy, complexity, and training time of thirty-three old and
new classification Algorithms - 1999
Obs.: (1) N(0,1) – distribuição normal padrão; UI(m,n) – distribuição uniforme inteira no intervalo (m,n); U(0,1) – distribuição uniforme no intervalo unitário; e,
(2) Foi gerado um único arquivo com pertubação aleatória para o banco Thy (35 atributos).
Quadro 2. Características dos arquivos de dados
Inicialmente foram levantados todos
os aspectos inicialmente considerados relevantes para o estudo dado que, por
hipótese, as características importantes são aquelas relacionadas com a
descrição das bases de dados em questão, relacionados abaixo:
|
Variáveis do Banco de Dados |
Descrição |
|
Nome
do Banco |
Identificação |
|
Quantidade
de registros |
Números
de registros no banco de dados |
|
Quantidade
de variáveis contínuas |
|
|
Quantidade
de classes das variáveis nominais |
|
|
Quantidade
de variáveis ordinais |
|
|
Dados
simulados? |
Se
os dados foram gerados com números pseudo-aleatórios |
|
Acurácia
da melhor regra |
Ver
item 3.2.1 |
|
Abrangência
da melhor regra |
Ver
item 3.2.1 |
|
Suporte
da melhor regra |
Ver
item 3.2.1 |
|
Tempo
de processamento |
Tempo
gasto no processamento num micro PENTIUM 200 Mhz |
|
Valor
final da avaliação |
Maior
valor da função de avaliação |
|
Se
o banco tem variáveis “noise” ou
não |
Se
o banco tem variáveis com perturbações aleatórias ou não. |
|
Função
de Avaliação |
Identificação
de uma das dez funções utilizadas |
|
Dimensão
do espaço de busca |
Produtório
do domínio das variáveis |
Quadro 3. Descrição das variáveis originais
O banco de dados foi
construído considerando que cada registro representa um experimento
realizado. A parametrização das
rodadas, executadas na ferramenta Rule-Evolver, foram as mesmas para todas as
funções de avaliação estudadas, conforme abaixo:
|
Total de Rodadas |
5 |
|
Total de Gerações |
50 |
|
Tamanho da População |
200 |
|
Normalização Linear |
SIM |
|
Tipo de Inicialização |
ALEATÓRIA |
|
Forma de Inicialização |
Incluindo o valor mediano |
|
Evolui as melhores regras |
SIM |
|
Substitui aleatoriamente os melhores |
NÃO |
|
Elitismo # |
2 |
|
Sementes # |
0 |
|
Taxa de Template |
30 |
0Operadores Genéticos
|
|
|
Crossover 1 ponto 0,3-0,3 |
0,65 |
|
Crossover 2 pontos 0,3-0,3 |
0,65 |
|
Crossover Uniforme 0,3-0,3 |
0,65 |
|
Mutação 0,1-0,3 |
0,08 |
Quadro 4. Parametrização do experimento
2.2 Limpeza
Esta etapa de limpeza
consistiu numa análise dos dados para a verificação de inconsistências ou
problemas. Foram constatados alguns
problemas na condução dos experimentos, relacionados a seguir:
Para os conjuntos de
dados SAT NOISE, DNA e DNA NOISE
nenhuma das funções de avaliação apresentou qualquer resultado. Na avaliação destes bancos de dados não foi
localizada nenhuma regra com abrangência, acurácia ou suporte diferente de zero
para qualquer das funções de avaliação testadas segundo a parametrização
padrão. Considerou-se que a população
de regras geradas na etapa de inicialização da população não abrangeu nenhuma
das informações constantes nos bancos.
Os arquivos DNA e DNA
NOISE possuem o maior número de variáveis categóricas (60 e 80), enquanto que o
arquivo SAT NOISE possui o maior número de variáveis contínuas (60).
LOPES [LOPE99] implementou três métodos de
inicialização da população:
Inicialização
aleatória sem sementes
Na faixa de valores do
atributo que ocorrem para o atributo objetivo especificado
Na faixa de valores do
atributo que ocorreu para o atributo objetivo especificado, incluindo o valor médio
Na faixa de valores do
atributo que ocorreu para o atributo objetivo especificado, incluindo o valor
mediano
Inicialização
aleatória com sementes de evoluções anteriores
Inicialização com
sementes de registros aleatórios do banco de dados
Dentre os métodos
apresentados poucos foram os resultados obtidos para os bancos de dados acima.
2.3 Enriquecimento
Um aspecto importante
a ser considerado era o grau de interseção entre os grupos. É de se esperar que quando os grupos
encontram-se perfeitamente separados o trabalho fica mais fácil e no caso
contrário mais difícil. Para tanto,
espera-se que determinadas funções atendam bem um aspecto, e outras, outros
aspectos. Assim, foi incorporado na
relação das variáveis o grau de interseção entre os grupos calculada com base
no estudo de [SHIH99] que
corresponde a razão de erro mediana dos diversos algoritmos de classificação
utilizados.
2.4 Transformação
Para comparação dos
resultados com a utilização das técnicas de Análise de Correspondência
Múltipla, tornou-se necessário transformar as variáveis contínuas em variáveis
categóricas com a utilização de algum critério. O critério escolhido procurou não introduzir nenhuma
tendenciosidade nos resultados. Para atingir este objetivo o critério se baseou
na própria distribuição dos dados analisados e em medidas robustas: até o
percentil 33 – Conceito ruim, entre o percentil 33 e o 66 – Conceito regular e,
maior que o percentil 66 – Conceito bom.
Em decorrência deste
conceito as variáveis apresentaram-se da seguinte forma:
|
Variável |
Definição |
|
ConInter – Conceito de Interseção dos Grupos, obtida pela mediana da razão de erro de classificação calculada em relação aos diversos algoritmos feita por [SHIH99]. |
Até 0,15545 – Baixa De 0,15545 até 0,27812 – Média Acima de 0,27812 – Alta |
|
EspC – Conceito do Tamanho do Espaço de Busca |
Até 10 14 – Pequeno De 10 14 até 10 36 –– Médio De 10 36 em diante –– Grande |
|
QvarCatC – Conceito de Quantidade de variáveis categóricas (inclui nominais e ordinais) |
0 variável – Baixa De 4 até 7 – Médio Acima de 7 - Alta |
|
QvarConC – Conceito de Quantidade de variáveis contínuas (inclui inteiras) |
Até 6 variáveis – Baixa De 6 até 15 variáveis – Média Acima de 15 variáveis - Grande |
|
QteregC – Conceito de Quantidade de Registros |
Até 500 registros – Baixa De 500 a 1500 registros – Média Acima de 1500 registros - Grande |
|
Tamanho do Banco – Conceito reunindo os aspectos de Quantidade de Registros, Quantidade de var. categóricas, contínuas e Espaço de Busca, levando-se em consideração: 1 para o conceito baixo; 2- conceito médio e 3 – conceito grande |
Até 6 pontos – Baixo De 7 a 8 pontos – Médio Acima de 8 pontos - Grande |
|
AvaliaC – Conceito da avaliação das regras geradas, pontuando-se da seguinte forma: Abrangência : Até 0,08 – Pequeno (1 ponto); De 0,08 a 0,63 – Média (2 pontos); e, Acima de 0,63 – Alta (3 pontos). Acurácia : Até 0,41 – Pequeno (1 ponto); De 0,41 a 0,95 – Média (2 pontos); e, Acima de 0,95 – Alta (3 pontos). Suporte : Até 0,001 – Pequeno (1 ponto); De 0,001 a 0,15 – Média (2 pontos); e, Acima de 0,15 – Alta (3 pontos). |
Até 5 pontos – Ruim De 6 a 7 pontos – Média De 8 a 9 pontos – Bom |
Quadro 5. Descrição
das variáveis na forma disjuntiva completa
Nesta fase foram
descartadas algumas variáveis em virtude de pouco acrescentarem ao conjunto
final das informações. Estas variáveis
após serem analisadas por sucessivos experimentos não foram incluídas nas
principais regras geradas e foram descartadas.
Algumas novas variáveis também foram criadas visando facilitar o
entendimento das regras geradas. Dentre
elas a variável avaliação que corresponde a soma das variáveis abrangência,
acurácia e suporte e aplicado o mesmo critério.
2.5 Mineração
Nesta etapa foram avaliadas as
hipóteses do trabalho. A primeira
hipótese investigou se o conjunto de funções de avaliação apresentavam o grau
de desempenho para as diferentes bases de dados estudadas. Na comparação efetuada verificou-se que para as estatísticas de
acurácia, abrangência e suporte foram verificadas que, estatisticamente,
apresentavam diferentes graus de desempenho.
Isto pode ser verificado pelo teste F para igualdade de médias aplicado,
cujo valor p é 0,000, portanto inferior a 0,1% para as três variáveis
estudadas.
A segunda hipótese investigou o
comportamento das funções de avaliação na geração de regras para grandes bancos
de dados. O resultado do teste F para
igualdade de média [NETE85] nos
mostra, pelo valor p = 0,526 que no aspecto
da acurácia o resultado não apresenta uma diferenciação entre os grupos quando
divididos pelo tamanho. Somente a
abrangência e o suporte mostram-se estatisticamente diferentes para os
diferentes grupos (valor p=0.000),
com o indicativo de quanto maior o grupo a qualidade diminui.
A terceira hipótese pesquisou o
relacionamento entre as características dos bancos de dados e a escolha da
função de avaliação. Apresentamos a
seguir as etapas de análise baseadas na Análise de Correspondência Múltipla e
na geração de regras por Evolução de Regras por Algoritmos Genéticos para a
obtenção dos critérios para a seleção das funções:
Considerando
totalidade dos registros como um único grupo definiu-se a variável Avaliação
como variável dependente e as demais como independentes (explicativas)
Considerando 3 grupos
baseados no resultado da variável Avaliação (1-Piores avaliações; 2-Medianas
avaliações; e, 3-Melhores avaliações), definiu-se a variável Avaliação como
dependente e as demais como explicativas
Considerando os grupos
2-Medianas avaliações e 3-Melhores avaliações, definiu-se a variável Função de
Avaliação como dependente e as demais explicativas para a obtenção dos
critérios para seleção de funções de avaliação.
As etapas descritas
nos mostra a busca por identificar a melhor regra para utilização das dez
funções de avaliação implementadas na ferramenta Rule-Evolver. Nas etapas 1 e 2 as regras obtidas não
incluiram a totalidade das possíveis combinações entre as variáveis, mas
obteve-se algumas regras simples de forma a entender o relacionamento entre a
função de avaliação e as características dos bancos de dados. As regras geradas na etapa 3 acabam por
resumir os conjuntos de regras geradas nas etapas anteriores.
Foram observadas
algumas compatibilidades nos perfis gerados pela Análise de Correspondência em
relação às regras geradas por Evolução de Regras por AG. Elas se encontram destacadas com referência
ao respectivo fator. No item seguinte é
indicada qual a função que gerou a regra logo a seguir.
3. Critérios para
seleção de funções
A geração das regras características
que serão utilizadas para futuras escolhas das funções de avaliação foram
obtidas a partir dos resultados dos experimentos com avaliação média ou boa,
separados em grupos por funções de avaliação, de forma a obter uma descrição de
cada um dos grupos selecionados e utilizando-se a técnica de Evolução de Regras
por AG. Os resultados são apresentados
a seguir:
|
FUNÇÃO 1 – NÚMERO DE ATRIBUTOS |
Bancos de dados que utilizaram a função de número 1
com baixa quantidade de variáveis categóricas e baixa quantidade de registros
apresentaram avaliação média ou bom |
|
FUNÇÃO 2 – DISTÂNCIA-ÓTIMA |
Bancos de dados que utilizaram a função de número 2 com
médio ou alto espaço de busca, média ou alta quantidade de variáveis
categóricas, média quantidade de variáveis contínuas e baixa ou média
quantidade de registros apresentaram avaliação média ou bom Bancos de dados que utilizaram a função de número 2
com média ou alta interseção entre os grupos, média e alta quantidade de
variáveis categóricas apresentaram avaliação média ou bom |
|
FUNÇÃO 3 – RECOMPENSA-ATRIBUTOS |
Bancos de dados que utilizaram a função de número 3
com baixo espaço de busca, alta quantidade de variáveis contínuas e baixa ou
média quantidade de registros apresentaram avaliação média ou bom Bancos de dados que utilizaram a função de número 3
com baixo espaço de busca e baixa quantidade de variáveis categóricas
apresentaram avaliação média ou bom |
|
FUNÇÃO 4 – CLASSIFICADOR BAYESIANO |
Bancos de dados que utilizaram a função de número 4
com baixa interseção entre os grupos e média ou alta quantidade de variáveis
contínuas apresentaram avaliação média ou bom Bancos de dados que utilizaram a função de número 4
com baixa ou média interseção entre os grupos apresentaram avaliação média ou
bom |
|
FUNÇÃO 5 – NÚMEROS-REGISTROS |
Bancos de dados que utilizaram a função de número 5 com
média ou alta quantidade de registros apresentaram avaliação média ou bom Bancos de dados que utilizaram a função de número 5
com médio espaço de busca apresentaram avaliação média ou bom |
|
FUNÇÃO 6 – ACURÁCIA COM RECOMPENSA ABRANGÊNCIA |
Bancos de dados que utilizaram a função de número 6
médio ou alto espaço de busca e média ou alta quantidade de variáveis
contínuas apresentaram avaliação médio ou bom |
|
FUNÇÃO 7 – ABRANGÊNCIA COM RECOMPENSA ACURÁCIA |
Bancos de dados que utilizaram a função de número 7
com baixa ou média interseção entre os grupos, médio ou alto espaço de busca,
média ou alta quantidade de variáveis categóricas, e média ou alta quantidade
de registros apresentaram avaliação média ou bom |
|
FUNÇÃO 8 – CORRELAÇÃO 2 GRUPOS |
Bancos de dados que utilizaram a função de número 8
com médio ou alto espaço de busca, média ou alta quantidade de variáveis
categóricas e média ou alta quantidade de registros apresentaram avaliação
média ou bom |
|
FUNÇÃO 9 – RULE INTEREST |
Bancos de dados que utilizaram a função de número 9
com médio ou alto espaço de busca e baixa ou média quantidade de variáveis
categóricas apresentaram avaliação média ou bom Bancos de dados que utilizaram a função de número 9
com médio espaço de busca e baixa ou média quantidade de variáveis
categóricas e alta quantidade de variáveis contínuas apresentaram avaliação
média ou bom |
|
FUNÇÃO 10 – CHI-SQUARE |
Bancos de dados que utilizaram a função de número 10
com baixa ou média quantidade de variáveis categóricas, baixa ou média
quantidade de variáveis contínuas e baixa quantidade de registros
apresentaram avaliação média ou bom |
Quadro 7. Critério para seleção de funções
Da mesma forma foi
utilizada a técnica de Análise de Correspondência Múltipla [BENZ92], para os experimentos que resultaram em médias e boas
avaliações. Diferentemente da primeira
parte, procurou-se identificar os perfis que se destacavam segundo a função de
avaliação utilizada. Foram obtidos os
seguintes resultados:
Perfil 1: Bancos de dados
que utilizaram a função 2 com média interseção entre os grupos, alto espaço de
busca, alta quantidade de variáveis categóricas, baixa quantidade de variáveis
contínuas e baixa ou alta quantidade de
registros apresentaram avaliação média ou bom.
Perfil 2: Bancos de
dados que utilizaram as funções 1, 9 ou 10 com média ou alta interseção entre
os grupos, médio espaço de busca, média quantidade de variáveis categóricas,
média quantidade de variáveis contínuas e baixa quantidade de registros
apresentaram avaliação média ou bom.
Perfil 3: Bancos de
dados que utilizaram a função 9 ou 10 com pequena interseção entre os grupos,
médio espaço de busca, média quantidade de variáveis categóricas, alta
quantidade de variáveis contínuas e alta quantidade de registros apresentaram
avaliação média ou bom
Perfil 3: Bancos de
dados que utilizaram as funções 2 ou 5 com alta interseção entre os grupos,
médio espaço de busca, alta quantidade de variáveis categóricas e média quantidade
de variáveis contínuas e média quantidade de registros apresentaram avaliação
média ou bom.
Perfil 4: Bancos de
dados que utilizaram as funções 3, 4 ou 10 com baixa interseção entre os
grupos, baixo espaço de busca, baixa quantidade de variáveis categóricas, média
quantidade de variáveis contínuas e baixa quantidade de registros apresentaram
avaliação média ou bom.
Os resultados
apresentaram-se bastante parecidos quando analisados em conjunto e
apresentaram-se agregados em mais de uma função de avaliação, enquanto que na
técnica de Evolução de Regras por AG os resultados descrevem uma ou mais regras
para cada função.
Durante a elaboração
deste trabalho, alguns aspectos importantes relacionados às funções de
avaliação foram levantados, sugerindo a criação de novas funções a serem
implementadas e testadas que foram relacionadas a seguir.
4. Novas Funções de
Avaliação
FUNÇÃO COMBINADA
(Acurácia, Abrangência e Suporte)
Esta função cria uma variação para
cada um dos aspectos da avaliação da regra.
Ao longo dos experimentos realizados nesta pesquisa verificou-se que em
nenhum dos casos foi possível uma regra que obtivesse um valor de 100% para as
três estatísticas. Quando a acurácia
obtinha um um valor muito alto, o valor da abrangência era relativamente baixo
junto com o suporte da regra. E para alguns casos não foram obtidos nenhum
valor para a abrangência. Assim sugiro
que no início do processo seja necessário um peso grande para abrangência e
suporte e baixo para a acurácia e, ao longo das gerações, ir variando o
conjunto de pesos para que ao final tenhamos um peso baixo para abrangência e
suporte e alto para acurácia. Esta
variação pode ser linear como está sendo feita com as probabilidades de seleção
dos operadores. Assim, teríamos a
função abaixo:
Função Combinada =
pesoacurácia* Acurácia + pesoabrangência* Abrangência +
pesosuporte* Suporte
Onde pesoacurácia
+ pesoabrangência + pesosuporte = 1 e os valores dos
pesos variam ao longo das gerações de um valor mínimo até um valor máximo a ser
definido no intervalo [0;1].
FUNÇÃO EQUILÍBRIO
Um aspecto bem interessante a
respeito das regras está no fato que a qualidade dos resultados depende não só
da função de avaliação, mas também dos dados.
Considerando as medidas de qualidade da regra (acurácia, abrangëncia e
suporte), muitas vezes é muito difícil termos um bom desempenho nestes três
aspectos. O objetivo desta função é
alcançar um valor de qualidade mínimo para os três aspectos. A função EQUILÍBRIO corresponde ao inverso
do coeficiente de variação das três medidas de qualidade da regra:
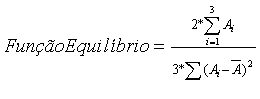
Onde:
Ai - Aspectos da regra = 1-Acurácia,
2-Abrangëncia e 3-Suporte
![]()
- Média dos três aspectos da regra
Esta inversão se torna
necessária em virtude do sentido da aptidão vir a ser: quanto maior o valor da
função mais próximos encontram-se os valores dos aspectos da regra, e
consequentemente menor o valor do coeficiente de variação.
5. Avaliação e
Verificação
A relação entre funções de avaliação
e características de banco de dados foi o objetivo principal deste
trabalho. Uma análise mais profunda das
funções de avaliação foi feita seguindo uma proposta de LOPES [LOPE99]. Foram adotadas
dois tipos de abordagens: Evolução de
Regras por Algoritmos Genéticos e Análise Correspondência Múltipla. A proposta de duas novas funções de
avaliação cumpre o objetivo secundário que poderá ser implementada num trabalho
futuro.
O conjunto de bases de dados
apresentavam características bem distintas uma das outras, apesar de serem, na
realidade, 16 bases de dados originais duplicadas com a utilização de variáveis
com perturbações aleatórias (ver Quadro 2).
Os resultados alcançados evidenciam
que o grau de desempenho das regras são diferentes para as funções de avaliação
estudadas. Uma associação inversa entre
o tamanho do banco de dados e a qualidade das regras encontradas foi confirmada
para os aspectos de abrangência e suporte, mas não para o aspecto da acurácia.
Dentre as características importantes
dos bancos de dados estudados para o problema de classificação as seguintes
variáveis foram identificadas com as que influenciam a escolha das funções de
avaliação:Grau de interseção entre os grupos, Qte variáveis categóricas, Qte
variáveis contínuas, Qte de registros, Tamanho do espaço de busca e Avaliação
das regras.
Para a obtenção dos critérios finais
de seleção de funções, verificou-se que a técnica de Evolução de Regras permite
uma flexibilidade maior na forma final das regras. Isto quer dizer que a abordagem da classificação dá lugar a pura
descrição do arquivo com o uso de regras, efetuando uma separação dos grupos
numa fase anterior. Assim, foi possível
obter um critério para cada uma das funções.
Com a abordagem de se utilizar o conjunto de todas as funções num único
arquivo, a chance de se obter um perfil para cada função independente é muito
pequena. As regras obtidas para cada
uma das funções não difere muito daquelas obtidas a partir da Análise de
Correspondência Múltipla.
6. Conclusão
Algoritmos Genéticos mostrou-se como
uma técnica inteligente extraindo conhecimento das bases de dados cujos
resultados se mostraram muito próximos ao da Análise de Correspondência. Algumas evidências apontam para uma
convergência maior quando a distribuição dos dados possui a média muito próxima
da mediana, pois os fatores obtidos na Análise de Correspondência Múltipla
representa a média obtida das influências das variáveis, enquanto que na
Evolução de Regras busca por um método mais robusto baseado no conceito de
freqüências. A grande vantagem
encontra-se numa interpretação mais simples de ser obtida.
O conceito da avaliação da regra é um
ponto a ser melhor estudado. Isto se
deve a necessidade da criação de um conceito relativo. Dada determinadas características do banco de
dados uma regra com valores baixos para as estatísticas de acurácia,
abrangência ou suporte pode representar o que de melhor pode ser expresso por
aquela regra. Na estatística temos
algumas medidas como o intervalo de confiança e o nível de confiança que nos
mostram o quão boa é uma estimativa.
Novas medidas de avaliação das regras podem ser pesquisadas.
O conceito de tamanho do banco de dados é também um ponto interessante para ser comentado, pois nesta
pesquisa vimos os seus aspectos: Quantidade de registros, quantidade de
variáveis e o domínio das variáveis.
São três dimensões de um problema que seguem em direções
perpendiculares. Enquanto que um
aumento para os três aspectos significa um aumento no processamento dos dados,
o espaço de busca pode ser influenciado mais pelo domínio das variáveis, pela
sua quantidade e talvez pela quantidade dos registros. Exemplificando somente em relação a dois
destes aspectos, consideremos um banco de dados com um dois campos e uma
quantidade enorme de registros (p.ex. 1 trilhão). A sua forma de apresentação pode variar até o seu inverso (1
trilhão de variáveis e dois registros), isto sem considerar o terceiro aspecto,
as dimensões das variáveis.
Bibliografia
[PASS00] Ruler-Evolver: An Evolucionary Approach for Datamining – aceito para
apresentação e publicação nos anais do 7th International Workshop,
RSFDC novembro99, Yamaguchi, Japan.
[PASS99] Busca de Conhecimento com Extração de Regras em RN e AG, Caso em Estudo
– aceito para apresentação e publicação nos anais do Congresso CLEI 2000,
setembro 2000, cidade do México.
[QUIN97] H. M. Quintella. Fatores Humanos e Tecnológicos de
Competitividade. Relatório de Pesquisa
UFF, (1997).
[TEIX00] S. Teixeira Jr, A Mina de Ouro debaixo dos Bits. Revista Exame – Fevereiro 2000.
[SHIH99] Lim, Loh, Shih. A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms, (1999).
[RADC95] N. J. Radcliffe (Project Manager) – GA-MINER: Parallel Data Mining with Hierarchical Genetic Algorithms Final Report, University of Edinburgh, (1995).
[ADRI96] Pieter Adriaans, Dolf Zantinge. DATA MINING. Syllogic. Addison-Wesley Longman, (1996).
[SAPO80] J. Bouroche, G. Saporta. ANÁLISE DE DADOS. Zahar Editores, (1982).
[WEIS98] Sholom M. Weiss, Nitin Indurkhya. PREDICTIVE DATA MINING A PRACTICAL GUIDE. Morgan Kaufmann Publishers, Inc., (1998).
[LOPE99] Lopes, Carlos Henrique Pereira, Classificação de Registros em Banco de
Dados por Evolução de Regras de Associação utilizando Algoritmos
Genéticos. Dissertação de Mestrado,
DEE, PUC-Rio, (1999).
[NETE85] Neter, John & Wasserman, William & Kutner, Michael H.,
Applied Linear Statistical Models, Second Edition, IRWIN, (1985).
[BENZ92] Benzécri, J. P., Correspondence Analysis Handbook, University of Paris VI – Paris France, Marcel Dekker, Inc. (1992).